prompt2model笔记
自然语言处理
prompt2model笔记
prompt2model是一个通过提示自动生成语言模型的方法
项目地址GitHub
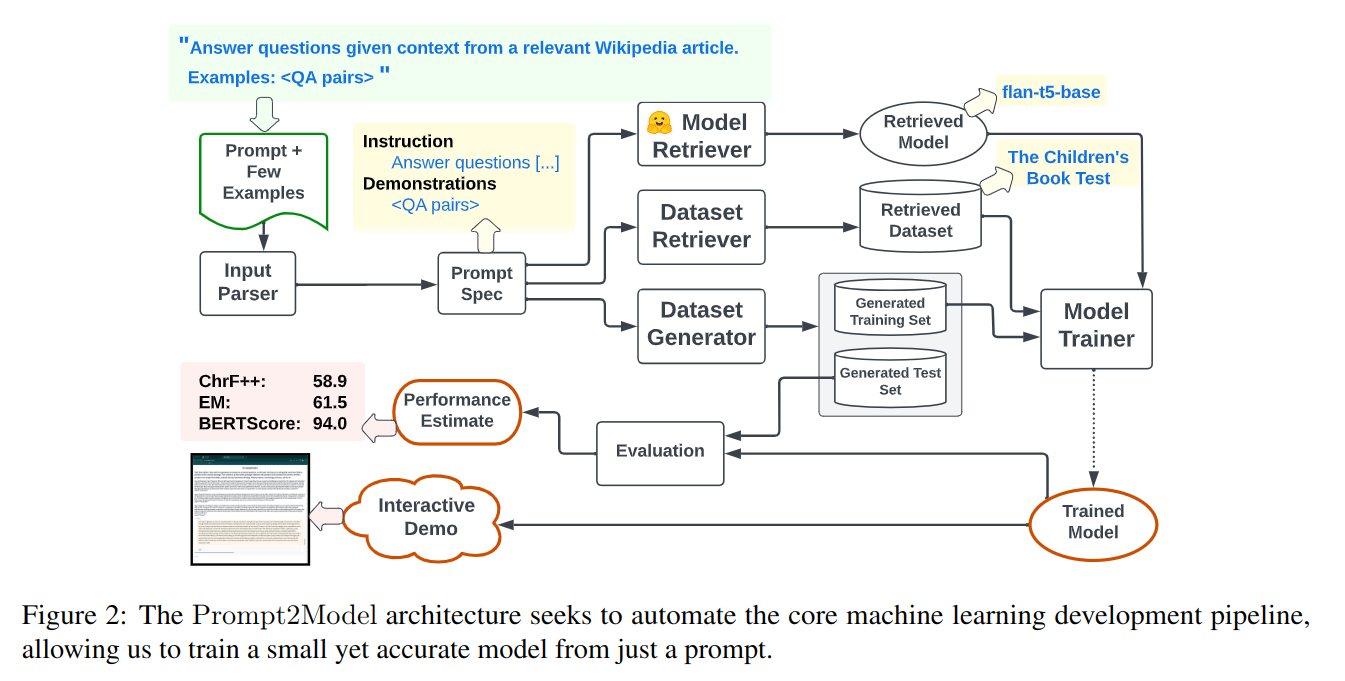
模型分为Prompt Parser,Dataset Retriever,Dataset Generator,Model Retriever几个部分
Prompt Parser
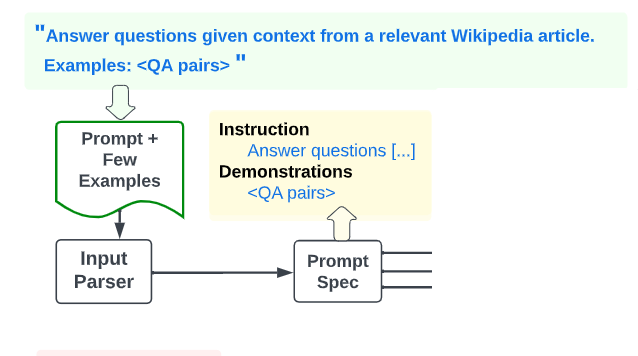
作者使用具有上下文学习的 LLM 来分割用户提示,在实验中使用 OpenAI gpt-3.5-turbo-0613。如果提供的指令被识别为英语以外的语言,就使用 DeepL API.2 将其转换为英语
Dataset Retriever
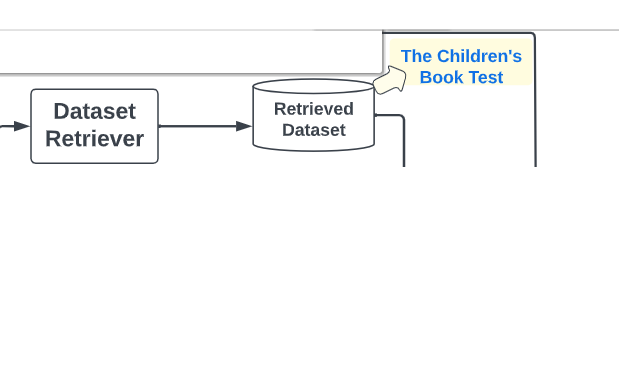
给定一个提示,首先尝试发现现有的手动注释的数据,可以支持用户的任务描述。数据集检索器有几个设计决策:
- 搜索哪些数据集。
- 如何索引数据集以供搜索。
- 3.用户任务需要哪些数据集列,应该忽略哪些列。 作者选用了 Viswanathan et al. (2023) 的方案,称为DataFinder
作者利用 DataFinder 训练的双编码器检索器对最相关的数据集进行排名。一旦确定了相关数据集,下一步是确定数据集的哪些列对应于用户指定的输入和期望输出。由于自动为任何数据集诱导正确的模式可能具有挑战性,所以作者采用了 human-inthe-loop 中的方法。将前 k 个数据集(默认情况下 k = 25)呈现给用户,并允许用户要么选择最相关的数据集,要么声明没有一个非常适合他们的任务。然后,要求用户从数据集的模式中识别输入和输出的适当列。
Dataset Generator
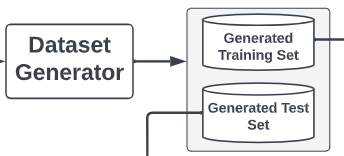 作者使用自动提示工程来生成不同的数据集,使用退火算法对生成的数据集进行排名。自一致性过滤来防止llm生成的伪标签。具体做法是通过选择最频繁的答案为每个唯一输入创建一个共识输出;在平局的情况下,启发式地选择最短的答案。使用了zeno-build做并行。
作者使用自动提示工程来生成不同的数据集,使用退火算法对生成的数据集进行排名。自一致性过滤来防止llm生成的伪标签。具体做法是通过选择最频繁的答案为每个唯一输入创建一个共识输出;在平局的情况下,启发式地选择最短的答案。使用了zeno-build做并行。
Model Retriever
这是一个检索类问题。作者选择encoder-decoder的架构,但是仍然有非常多的选择,像Salesforce/codet5-base,MaryaAI/opus-mt-ar-en-finetuned-ar-to-en,所以作为一个检索类问题使用用户的指令作为查询,搜索 Hugging Face 上模型的所有文本描述。
 ,考虑到对模型的描述一般是比较稀疏并且包含大量模板文本,这里作者使用gpt-3.5-turbo生成了模型可能的描述,用 BM25 算法来计算查询模型相似度分数。
,考虑到对模型的描述一般是比较稀疏并且包含大量模板文本,这里作者使用gpt-3.5-turbo生成了模型可能的描述,用 BM25 算法来计算查询模型相似度分数。
为了模型易部署,作者过滤了大于3gb的所有模型,同时引入了一个直觉,下载量越高的模型效果越好。
