RoboTAP笔记
多模态
发布于
RoboTAP笔记
RoboTAP是一种基于点追踪技术的少样本视觉模仿方法,可以实现机器人在多个任务和场景中的精准操作。
项目主页GitHub
RoboTAP不需要任何特定于任务的训练或神经网络微调。由于TAP的普适性,作者发现添加新任务(包括调整超参数)只需几分钟,这比我们熟悉的任何操纵系统都快几个数量级。作者认为这种能力在大规模自主数据收集和作为解决现实任务的解决方案方面可能非常有用。RoboTAP在需要快速教授视觉运动技能并且可以轻松演示所需行为的情况下最有用。
RoboTAP存在一些重要的限制。首先,低级控制器是纯视觉的,这排除了复杂的运动规划或力控制行为。其次,目前计算运动计划一次并在没有重新规划的情况下执行它,这可能会导致单个行为失败或环境意外改变。
作者在论文中指出他有四个贡献
- 在密集跟踪方面制定多任务操作问题
- RoboTAP的具体实现是什么,在哪里以及如何以visual-saliency,temporal-alignment, 和 visual-servoing的形式解决问题
- 一个新的密集跟踪数据集,其中包含为RoboTAP任务量身定制的ground-truth人工注释,并在专注于真实世界机器人操作的TAP-Vid基准上进行评估
- 描述了RoboTAP在涉及精确多体重排、变形物体和不可逆行动的一系列操作任务中的成功和失败模式的实证结果。
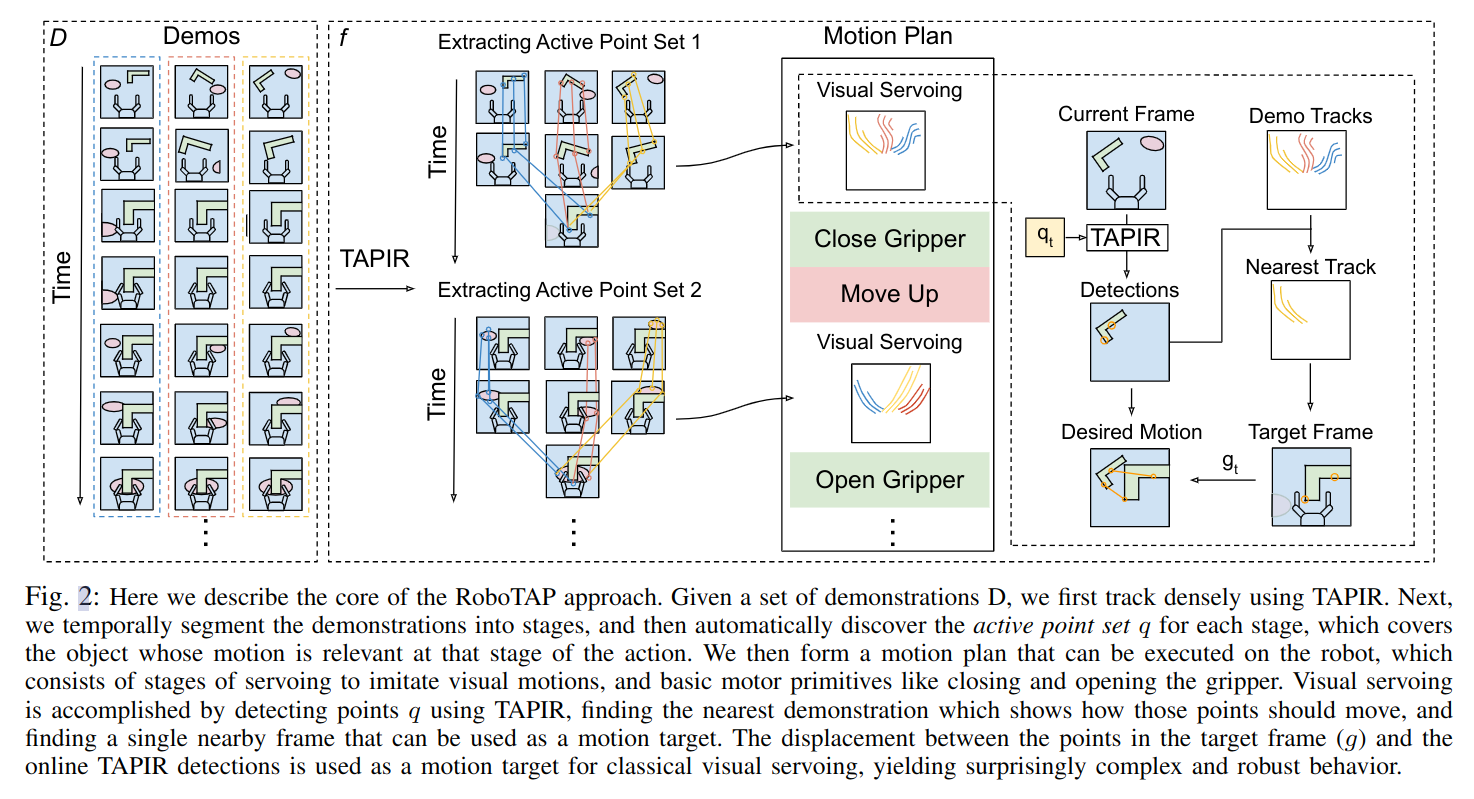
RoboTAP方法的核心是利用TAPIR密集地跟踪一组演示,将演示分段,并自动发现每个阶段的活动点集q,该点集覆盖在该动作阶段相关的物体上。然后,我们形成一个可以在机器人上执行的运动计划,其中包括模仿视觉运动和基本的电机原语,例如关闭和打开夹爪的阶段。通过使用TAPIR检测点q,找到最近的演示,显示如何移动这些点,并找到可以用作运动目标的单个附近帧来实现视觉伺服。将目标帧(g)和在线TAPIR检测之间的位移用作经典视觉伺服的运动目标,从而产生出奇异复杂和强健的行为。
