Dual-Stream Diffusion Net for Text-to-Video Generation笔记
文字生成图片
发布于
Dual-Stream Diffusion Net for Text-to-Video Generation笔记
这篇论文提出的模型架构是Dual-Stream Diffusion Net(DSDN),它是一种双流扩散网络。
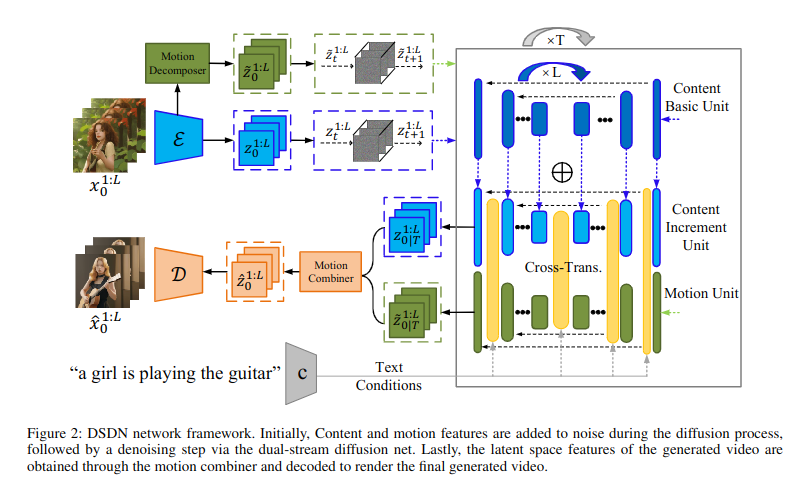
首先,视频内容通过一个一个编码器编码成内容特征和一个动作编码器编码成动作特征,并通过一个增量学习模块进行更新。前向扩散过程没有使用DDPM而是使用了 Hierarchical Text-Conditional Image Generation with CLIP Latents 这篇论文提出的方法。
为了对齐生成的内容和运动,设计了一个双流转换交互模块来通过交叉注意力实现两个分支之间的信息交互和对齐。
最后引入了运动合成器来简化运动信息的操作。
