AnyDoor笔记
AnyDoor笔记
在这项工作中,香港大学,阿里联合提出了提出了 AnyDoor,这是一种基于扩散的生成器,可以进行对象隐形传态。这项研究的核心贡献是使用判别 ID 提取器和频率感知细节提取器来表征目标对象。在视频和图像数据的不同组合上进行训练,我们在场景图像的特定位置合成对象。AnyDoor 为一般区域到区域的映射任务提供了通用解决方案,并且可以为各种应用有利可图。
AnyDoor的模型架构图如下图所示,看起来还是比较清晰的,我们一部分一部分来看
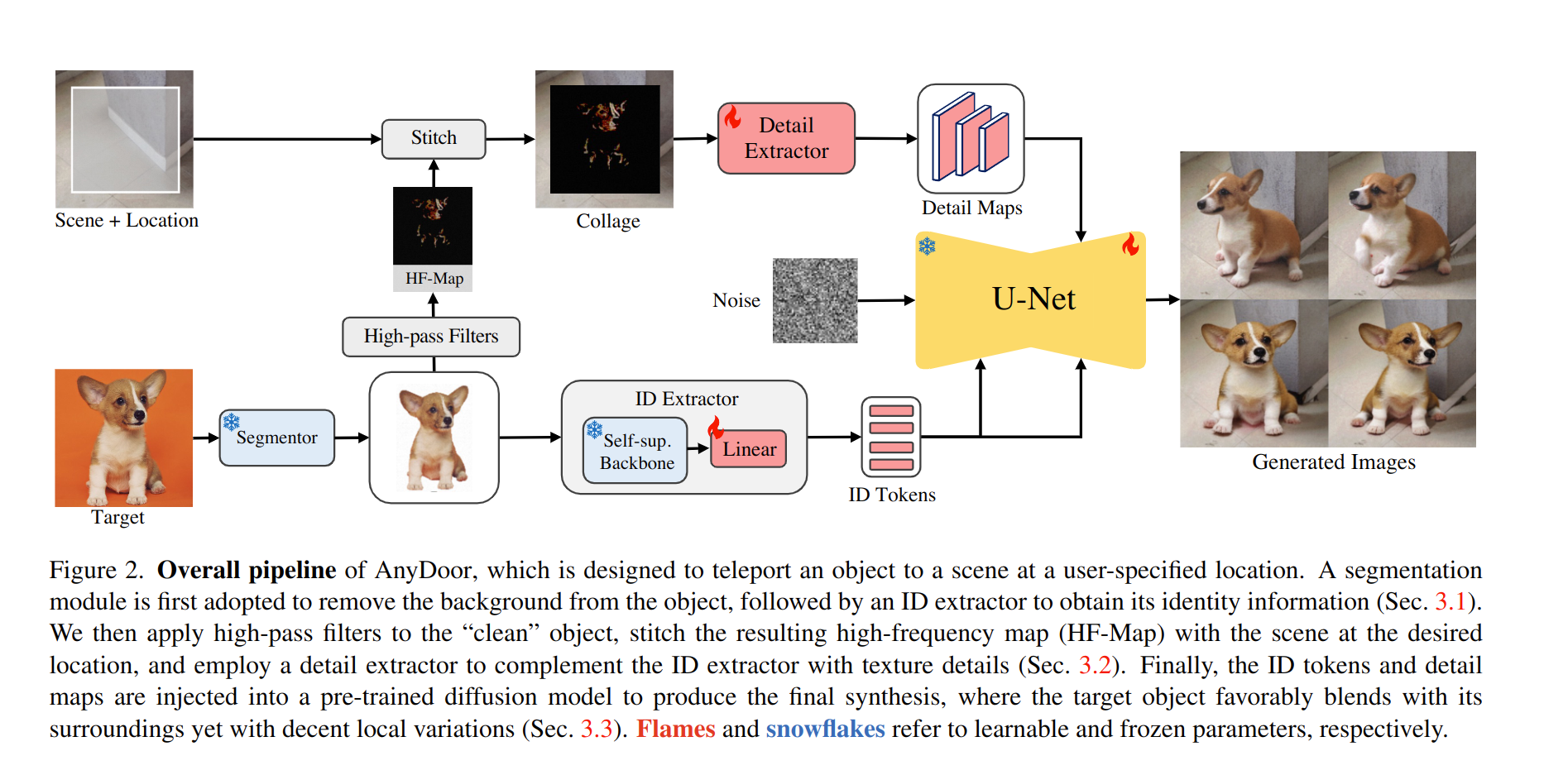
ID特征提取器
一般都选择CLIP的图像编码器编码一个图像对象。但是CLIP 是由粗略描述的文本对训练而来的,所以CLIP 只能给出一些语义上的描述,但是很难对每个物体的特征做出分辨。所以作者做出了两点更新,背景移除和自监督的表示。
对应到整个pipeline就是这部分

背景移除
背景移除就是使用一个分割模型将背景删除,然后将目标物体和背景中心对齐。可以使用一些自动的模型(例如Segment Anything),和可交互式的模型
自监督的表示
作者说在这个工作中他们发现自监督的模型可以很好的保留物体的判别特征。在大规模数据集上进行预训练,自监督模型自然配备了实例检索能力,可以将对象投影到增强不变的特征空间(augmentation-invariant feature space,经过抱大佬大腿,这个特征空间是说经过图像增强语义不变)中。作者采用了DINO2作为编码器,得到了一个全局的特征 和一个局部的特征 ,使用一个线性层将这两个向量投影到UNet需要的维度,然后合并俩个向量使用,最后的向量是
细节特征提取
作者认为,由于 ID 令牌会丢失空间分辨率,因此它们很难充分保持目标对象的精细细节。所以使用互补的细节作为生成过程中额外的指导。
使用拼贴作为控件可以提供强大的先验,作者尝试将“背景移除的对象”缝合到场景图像的给定位置。通过这个拼贴,可以观察到生成保真度的显着改进,但生成的结果与缺乏多样性的给定目标过于相似。面对这个问题,作者探索设置信息瓶颈以防止拼贴给出太多外观约束。实际上就是设计了一个高频映射来表示对象,它可以保持精细细节,但允许通用的局部变体,如手势、照明、方向等。
对应pipeline的这部分,
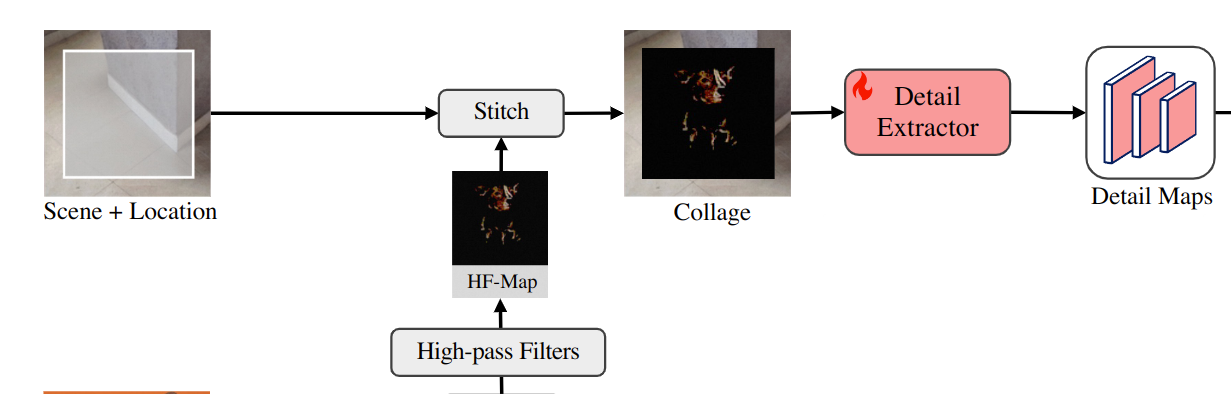
作者使用了这样一个公式来提取高频图 是一张RGB的图像(上一步背景移除得到的图片), 和 是水平和垂直Sobel kernel,这里被用作高频滤波器,代表卷积,代表逐元素乘法。侵蚀掩码 来过滤目标对象外部轮廓附近的信息。
在得到高频图后,根据给定的位置将其拼接到场景图像上,然后将拼贴传递给细节提取器。细节提取器是一个 ControlNet 中的UNet 编码器,它生成一系列具有分层分辨率的细节图。
特征注入
在获得 ID 标记和细节图后,将它们注入到预训练的文本到图像扩散模型中以指导生成。作者选择了stable diffusion,它将图像投影到潜在空间中,并使用UNet进行概率采样。我们注意到预训练的 UNet 为 ,它从初始潜在噪声 开始去噪,并将文本嵌入 c 作为生成新图像潜在 的条件。训练监督是均方误差损失为 是ground-truth,t是反向过程的步数, 是去噪的超参数。
在这项工作中,文本嵌入 c 被替换为前面的 ID 标记,这些标记通过交叉注意注入到每个 UNet 层。对于细节图,将它们与每个分辨率的 UNet 解码器特征连接起来。在训练期间,模型冻结 UNet 编码器的预训练参数以保留先验并调整 UNet 解码器以适应我们的新任务。
训练策略
图像文本对
理想的训练样本是“不同场景中同一对象”的图像对,但是这些数据集不能直接由现有数据集提供。作为替代方案,以前的工作利用单个图像并应用旋转、翻转和弹性变换等增强。然而,这些幼稚的增强不能很好地代表姿势和视图的真实变体。
为了解决这个问题,在这项工作中,作者使用视频数据集来捕获包含相同对象的不同帧。
自适应的训练步长
虽然视频数据有利于学习外观变化,但由于分辨率低或运动模糊,帧质量通常不能令人满意。相比之下,图像可以提供高质量的细节和通用的场景,但缺乏外观变化。
为了利用视频数据和图像数据,作者开发了自适应时间步采样,使不同模态的数据有利于去噪训练的不同阶段。stable dissusion为每个训练数据均匀地采样时间步长 (T)。然而,观察到初始去噪步骤主要集中在生成整体结构、姿势和视图;后面的步骤涵盖了纹理和颜色等精细细节 。因此,对于视频数据,可以增加了在训练期间采样早期去噪步骤(大 T)以更好地学习外观变化的可能性。对于图像,增加了后期步骤(小 T)的概率来学习如何覆盖精细细节。
