StableDiffusion笔记
文字生成图片
Stable Diffusion 是一个图像生成方法,由 Stability AI and Runway 在LDM1 的基础上提出。在GitHub有很多他的实现和应用234 ,其中2 是最早的实现版本,3 是V2版本,由 Stability AI 完成。
整体结构
flowchart TD
subgraph Input-noisy
Random-seed --> latent-Gaussian-noise
end
subgraph Input-prompt
prompt --> TextEncoder --> TextEmbaddings
end
latent-Gaussian-noise -->Unet{Unet-with-MultiAttention}
TextEmbaddings-->Unet
Unet --> predict-noisy --sampling-steps-->Unet
predict-noisy --> Decoder --> Image
在一开始,StableDiffusion会通过一个随机数种子生成一张在隐空间下的随机噪声,同时通过一个文本编码器对输入的prompt进行编码,生成一个文本向量。随机噪声和文本向量会一块送入Unet,经过DDPM的步骤得到一张隐空间下的图片,通过一个解码器得到完整的图片。这里的Unet做出了改进,中间加入了交叉注意力机制。
Unet-with-MultiAttention
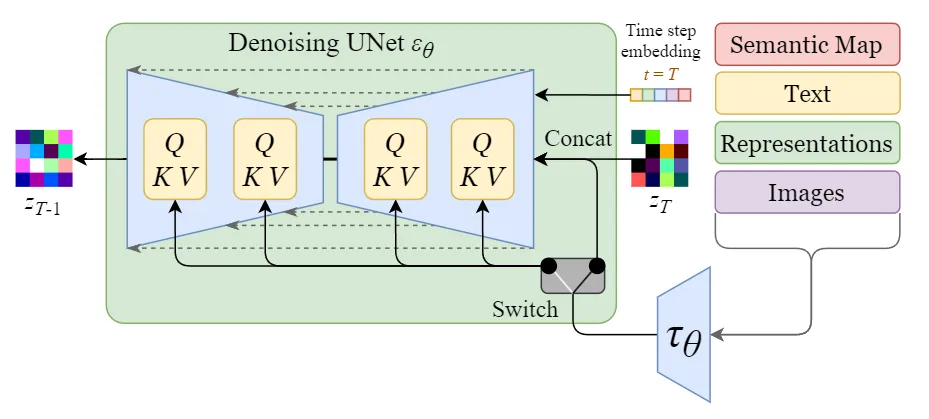 图中Switch用于在不同的输入之间调整。
图中Switch用于在不同的输入之间调整。
- 文本数据通过一个文本编码器(一般是CLIP的文本编码器)将文本转换为向量,投影到Unet上
- 图像,语义图,表示等直接送入Unet
反向扩散过程中输入的文本向量和隐空间下的噪声图片需要经过 轮的Unet网络,每一轮预测一个噪声,噪声图减去这个噪声,得到的图片继续送入Unet进行下一轮
参考文献
Footnotes
-
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., & Ommer, B. (2022). High-Resolution Image Synthesis with Latent Diffusion Models. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Presented at the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA. https://doi.org/10.1109/cvpr52688.2022.01042 ↩
-
CompVis. (n.d.). GitHub - CompVis/stable-diffusion: A latent text-to-image diffusion model. GitHub. Retrieved May 29, 2023, from https://github.com/CompVis/stable-diffusion ↩ ↩2
-
Stability-AI. (n.d.). GitHub - Stability-AI/stablediffusion: High-Resolution image synthesis with latent diffusion models. GitHub. Retrieved May 29, 2023, from https://github.com/Stability-AI/stablediffusion ↩ ↩2
-
AUTOMATIC1111. (n.d.). GitHub - AUTOMATIC1111/stable-diffusion-webui: Stable Diffusion web UI. GitHub. Retrieved May 29, 2023, from https://github.com/automatic1111/stable-diffusion-webui ↩
