I3D笔记
发布于
I3D笔记
I3D是一个视频理解模型,采用双流网络的架构,他的核心贡献是提出了如何对2d网络进行膨胀操作,同时提出了一个新的数据集 Kinetics
工作回顾
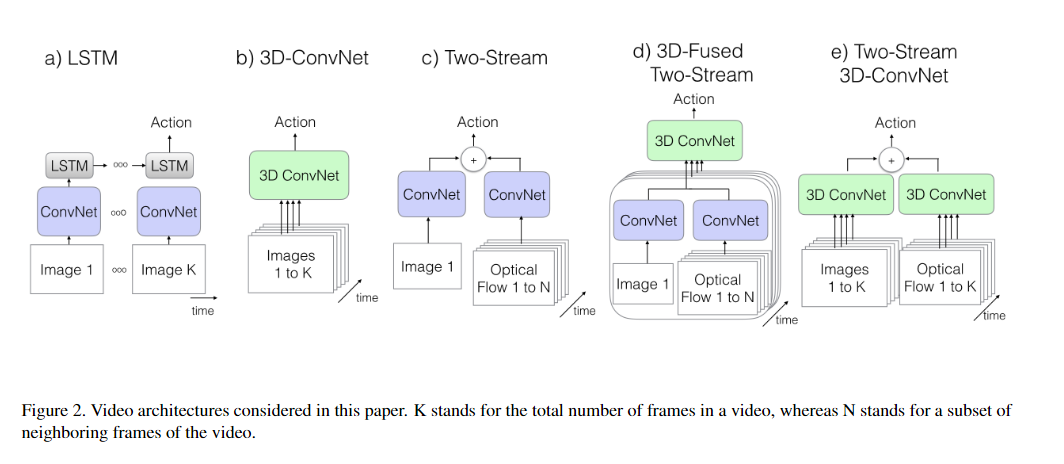
在以前,视频理解有三种做法
- LSTM
- 3D ConvNets
- Two-Stream Networks(双流网络)
Two-Stream Inflated 3D ConvNets
这篇文章提出的模型被称为 Two-Stream Inflated 3D ConvNets
Inflate 是模型的核心操作,含义是将一个2d模型”膨胀”成3d模型,做法很简单,就是把一个 的层变成 ,同时也将参数复制了 遍。
Kinetics
在视频领域,在一个足够大的数据集上训练一个动作分类网络,当应用于不同的时间任务或数据集时,是否会有类似的性能提升是一个悬而未决的问题。构建视频数据集的挑战意味着大多数流行的动作识别基准。
Kinetics 有400个人体动作类,每个类有400多个例子,每个都来自一个独特的 YouTube 视频
整体架构
作者选择了 Inception-v1 构建整个神经网络(作者当时不适用Inception-v1是因为当时认为Inception在视频理解更合适,但架不住ResNet 太棒了,作者在18年也换成了ResNet)
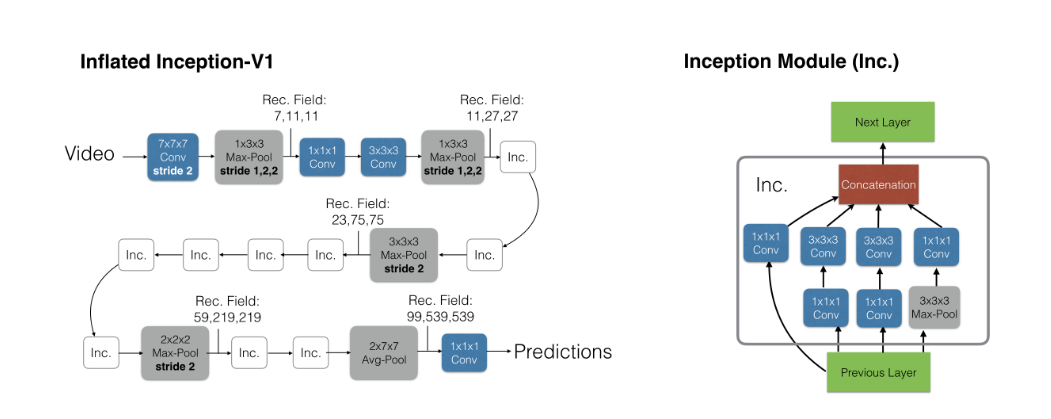
图中的Inc. 就是经典的Inception-v1 块了,只是做了Inflating 操作
