文字生成图片综述
文字生成图片
文字生成图片综述
背景
根据文字生成图像,是近几年大模型领域和多模态比较热门的研究。以 NovelAI,waifu 等为代表的二次元模型极大地拓展了 stable diffusion 12模型和生态的想象空间。例如原本做 AIGC 生成小说的 NovelAI 推出了自己的二次元图像生成模型,基于 SD 算法框架和 Danbooru 二次元图库数据集进行训练和优化。像 NovelAI 这类的二次元模型对于用户输入的描述词的专业程度要求较高,也由社区自发整理了大量的魔典(prompt).精确控制图像的生成也是 AI 绘画的一个发展方向,各种可以控制人物动作,位置的方法345被提出.最近 openai 也开源了他们最新的研究 Consistency Models6 ,可以 1s 内生成多张图片。此外,stable diffusion 也被用在了 3d 模型的生成方面,例如 dreamfusion7,Point-E8 等。
图像生成
hypernetwork
hypernetwork 是一种神经网络的处理方法9 主要方法是通过一个神经网络影响另一个神经网络的参数,其中最具有代表性的就是 GAN1011 了.
扩散模型
扩散模型第一次在12 中被提出,被称为 Diffusion Probabilistic Model,之后提出的 DDPM13中被改进。之后 DDPM 也衍生出了诸多版本。发布在 CVPR2022 的 LDM1将图片放到隐空间上实现了图片高质量合成并提出了内容引导机制,可以通过 prompt 让图片生成特定内容。一年后 LDM 衍生除了 stable diffusion21,掀起了 ai 画图的热潮。
DDPM
DDPM 分为前向过程和反向过程。DDPM 假定整个过程都是一个参数化的马尔科夫链,在前向过程中对数据逐步增加高斯噪声直到数据变成一个高斯噪声,反向过程中使用 U-Net14 预测反向添加的噪声进行去噪。
从 是扩散模型的逆过程,这是在生成数据的时候是从一个随机的高斯分布采样一个信号,逐步通过去噪声恢复目标信号, 这个过程的解析式是未知的。前向过程是从 ,对一个真实信号逐步加噪声,通过选取合适的噪声尺度,理论上在一定步数以后真实信号也会变成高斯信号,可以把这个过程表示为 。
利用重参数化技术,我们可以得到从 0 到 t 的直接采样可以得到 ,其中 表示前向过程每一步的方差。这样在训练的时候我们就可以随机采样一个时刻,然后计算处这个时刻的 。 是未知的,但是可以求出 的解析解 DDPM 中推导出了基于噪声误差的损失函数,即通过网络估计噪声,而不是直接估计 ,损失函数是
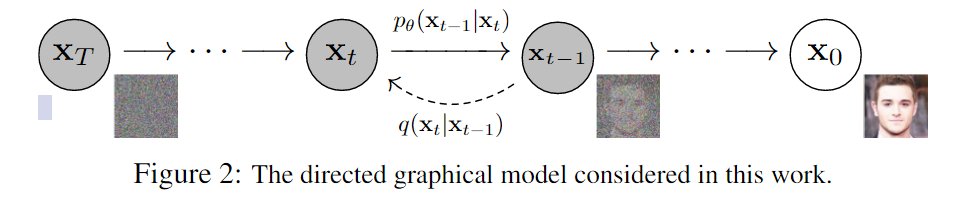
DDPM 也有几个改进版本,例如 DDIM15 . DDIM 采用更小的采样步数来加速生成过程。
LDM
为了降低训练模型时所需要的训练资源,使用 latent space 的 LDM1被提出.尽管允许通过对相应损失项的低采样忽略感知上无关的细节,但这一步仍然需要在像素空间中进行昂贵的函数计算,这导致了巨大的计算时间和能源需求。
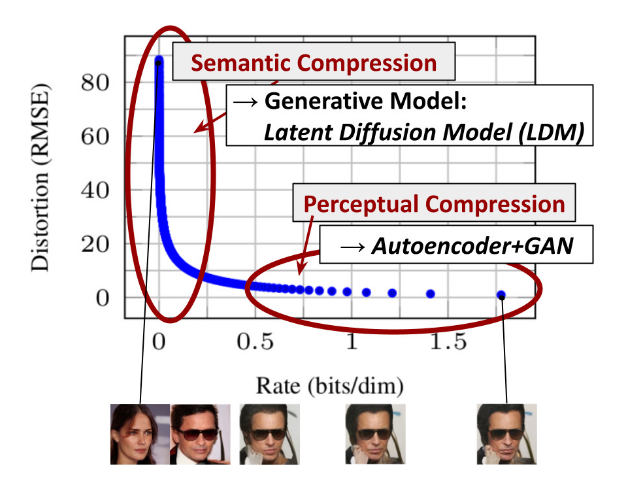
横轴是隐变量每个维度压缩的 bit 率,纵坐标是模型的损失。模型在学习的过程中,随着压缩率变大,刚开始模型的损失下降很快,后面下降很慢,但仍然在优化。模型首先学习到的是 semantic 部分的压缩/转换(大框架),这一阶段是人物 semantic 部分转变,然后学习到的是细节部分的压缩/转换,这是 perceptual 细节处的转变。
LDM 将图像从变换到 latent space 上,采用了 encoder-decoder 的机制,图像生成又回到了以前的架构上,并引入了自注意力机制,将扩散模型转换为更有效的图像生成器。给定图像 ,编码器 会将图片编码到 ,解码器 会从 latent space 中重建图像。给定 , 。更重要的是下采样倍数 ,作者采用的是
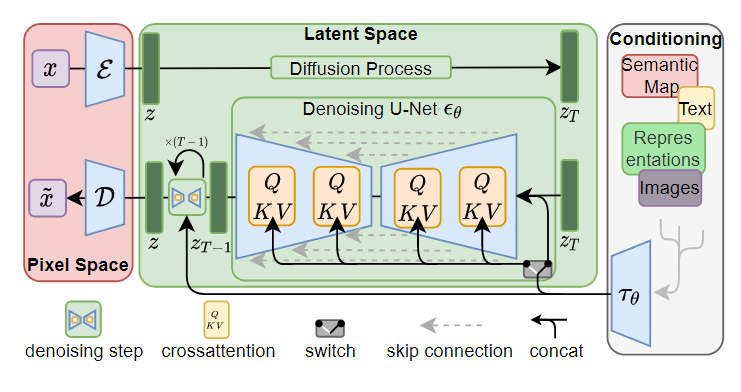
Conditioning Mechanisms,这里的条件可以是文字、图像等。将不同模态不同大小的条件转换为一个中间表达空间。通过这种方法可以实现 prompt 指导图象生成。
Consistency Models
Consistency Models6 是 openai 提出的最新的一种图片生成方法
diffusion13 的采样过程,从先验分布 出发,推导采样过程 .
Consistency Models 假设存在一个函数,对于上述过程中的每个点,都能输出一个相同的值,即 对于轨迹起点 ,有 .那么对于轨迹中任意一点,我们代入先验分布, 即可得到 。这样也就完成了一步采样。
文字生成图片
文字生成图片一个重要的前提条件是建立文字和图片的联系。CLIP 首先通过对比学习的方式实现了文字图片联系。FLIP 和 A-CLIP 对 CLIP 进行了改进。DALLE,GLIDE,DALLE2 是 OPENAI 发布的文生图模型,GLIDE 实现了无分类器引导的图片生成,DALLE2 引入 CLIP 进行图片生成。Imagen 主要使用文字内容进行训练,图片则先生成小图再超分放大。
CLIP
OPENAI 提出的 CLIP16通过对比学习的方式建立了文字和图片的联系.在训练过程文字和图像分别经过一个文字编码器和图像编码器得到一个对应的向量,将对应的文字向量和图像向量作为正样本,不对应的向量作为负样本进行对比学习。
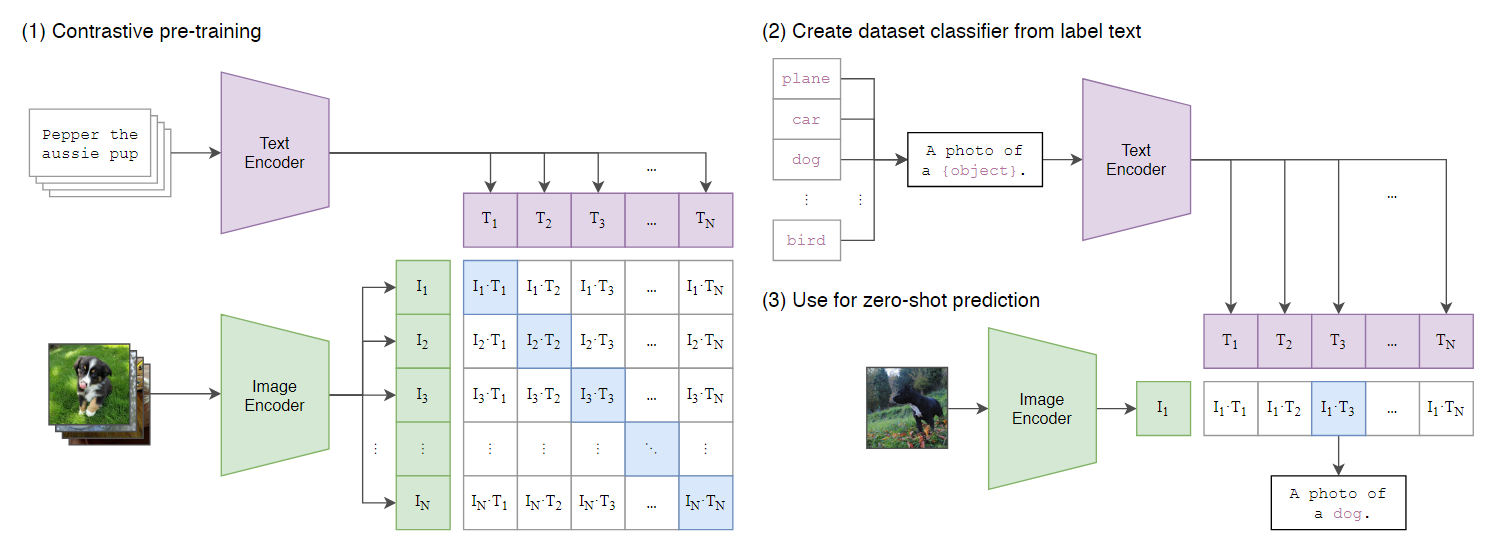 考虑到大部分的数据集的标签都是以单词的形式存在的,比如“bird”,“cat”等等,然而在预训练阶段的文本描述大多都是某个短句,为了填补这种数据分布上的差别,作者考虑用“指示上下文”(guide context)对标签进行扩展。可以用
考虑到大部分的数据集的标签都是以单词的形式存在的,比如“bird”,“cat”等等,然而在预训练阶段的文本描述大多都是某个短句,为了填补这种数据分布上的差别,作者考虑用“指示上下文”(guide context)对标签进行扩展。可以用a photo of a {object}作为文本端的输入。推理过程先给定一个提示A photo of a {object} ,这里的 object 可以填入任意的内容,然后通过一个文字编码器得到与输入内容分别对应的一组向量。同时图片经过一个图像编码器得到一个向量,将图片得到的向量分别和填入内容得到的向量计算余弦相似度,相似度最大的则是目标的描述。
CLIP 改进
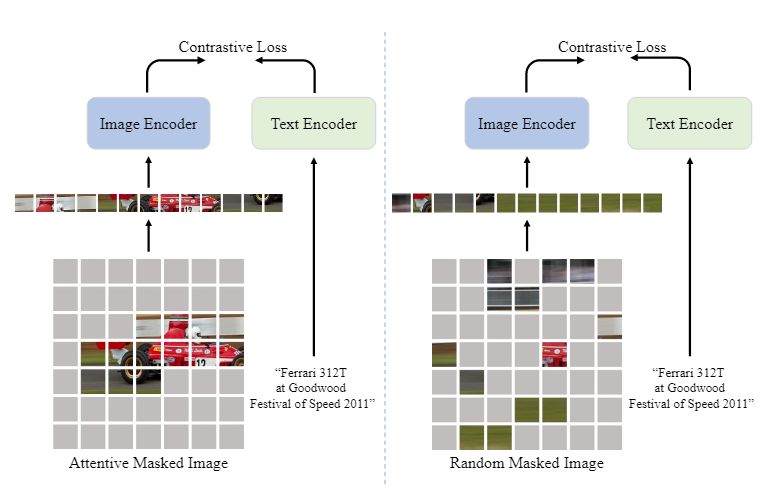
何凯明团队提出的 FLIP17通过对图片加入 mask 有效提升了 CLIP 的推理速度,同期的 A-CLIP18通过加入注意力机制保留了图像中具有语义信息的部分,避免随意加入 mask 对模型的训练造成影响。如图左侧是 A-CLIP 的过程,右侧是 FLIP 的结果。
GLIDE19采用无分类器指导的扩散模型实现了图片生成。GLIDE, Guided Language to Image Diffusion for Generation and Editing,是 OpenAI 推出的文本引导图像生成模型,,但受到的关注相对较少。它甚至在 OpenAI 网站上也没有专门的帖子。GLIDE 生成分辨率为 256×256 像素的图像。实际上在论文中 DALLE2 被称为 unCLIP。参数量上 5B 的 GLIDE 的 FID 得分超过了 12B 的 DALLE
DLALL-E2
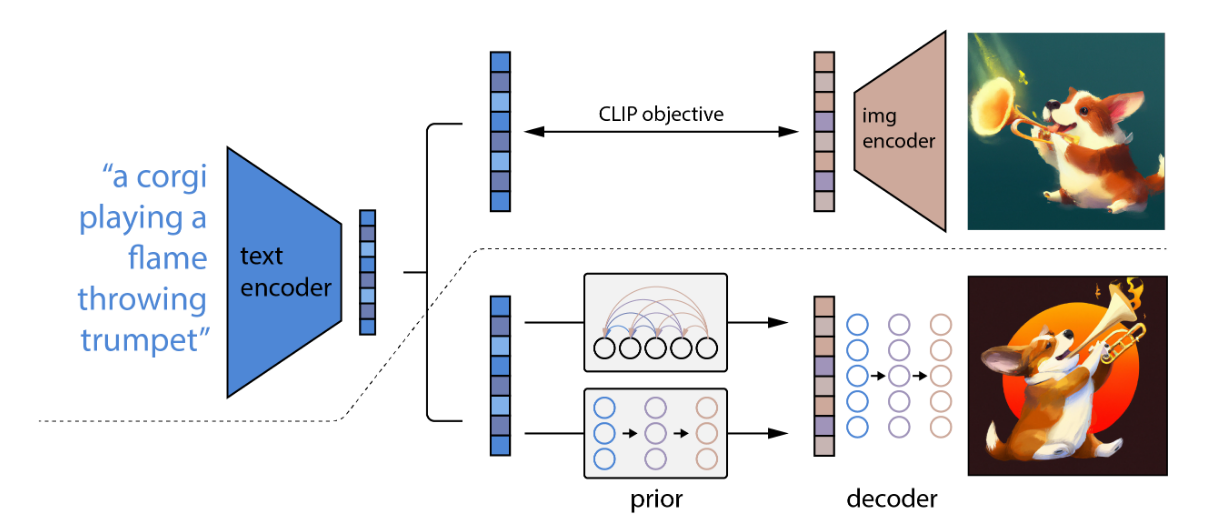
DALL·E220的架构加入了 CLIP16,通过锁住 CLIP 的文本编码器和图像编码器可以建立文字和图像的联系,加入 prior 和 img decoder 两个先验, 训练 prior,使文本编码可以转换为图像编码,并训练 decoder 生成最终图像。
Imagen
谷歌的 Imagen21的语言模型替换成了谷歌自家的 T5-XXL,图像生成部分则是先生成小图像再上采样生成大图像,这是因为纯文本训练数据要比高质量图文对数据容易获取的多.
LoRA 微调
Low-Rank Adaptation of Large Language Models (LoRA)22 是一种训练方法,可以加速大型模型的训练,同时消耗更少的内存。最初是被用在语言模型上的,在文本理解,文本生成上都取得了不错的效果
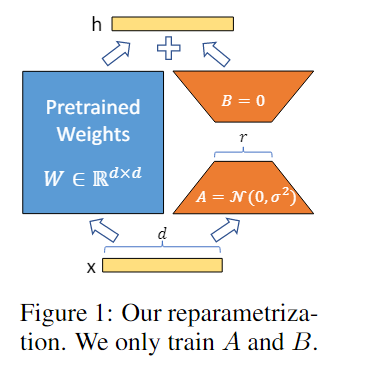
做法是在原模型旁边增加一个旁路,通过低秩分解(先降维再升维)来模拟参数的更新量。训练时,原模型固定,只训练降维矩阵 A 和升维矩阵 B,推理时,可将 BA 加到原参数上,不引入额外的推理延迟。此外这还是一个可拔插的模块,可以根据需要选择不同的 rank
LoRA 的应用包括文字生成图片和图片生成图片.23 是第一个使用 LoRA 微调扩散模型的项目。Chinese-alpaca-lora24 是一个由华中师范大学同学维护的中文语言模型,使用 LoRA 进行微调。
DreamBooth25 也可以与 LoRA 结合进行微调26
图像编辑
图像编辑也是文字生成图片的重要应用。Imagic 输入一个文本图像和目标文本,通过多阶段的方法对齐文本和图像编辑图像。ControlNet 通过复制参数为锁住的和可训练的,使模型可以为特定任务进行微调。同时 ControlNet 可以传入 openpose 人的位姿图,canny 边缘图,深度图,Hough 变换生成的图等各种图片可控得生成图片。Google 的 DreamBooth25 提出了一种使用少量图片进行微调的方式,提供一种用户训练自己模型的方法。prompt2prompt 通过更改图片对应的 map 的方式特定更改图片。
Imagic
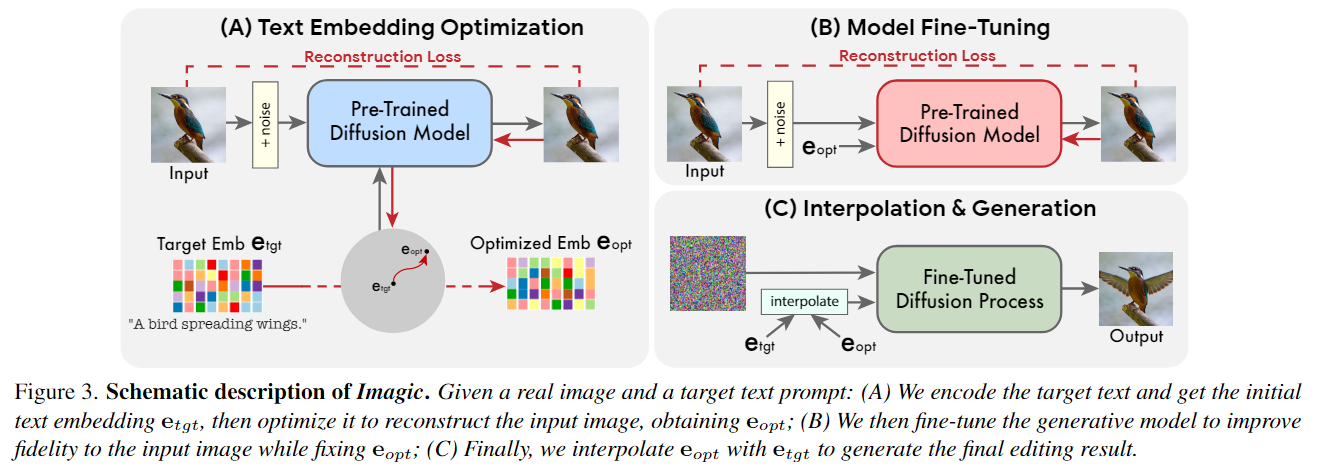
Imagic3提出的方法只需要一个输入图像和一个目标文本(所需的编辑)。它生成一个与输入图像和目标文本一致的文本嵌入,同时微调扩散模型以捕获特定于图像的外观。Imagic 通过多阶段的方法实现了图片编辑,分为优化文本嵌入,微调扩散模型。在优化的嵌入和目标文本嵌入之间进行线性插值三个过程。首先优化文本嵌入,使其生成与输入图像相似的图像。然后,对预训练的生成扩散模型(以优化的嵌入为条件)进行微调,以更好地重建输入图像。最后,在目标文本嵌入和优化后的文本之间进行线性插值,得到一个结合了输入图像和目标文本的表示。然后将这种表示传递给带有微调模型的生成扩散过程,输出最终编辑的图像。
ControlNet
ControlNet4通过对参数复制,将参数分为锁住的和可训练的。锁着的参数从大量的图片文本对中学习更通用的信息,可学习的参数在特定的任务上进行微调,让模型在个人电脑和大型计算集群上都可以获得很好的训练效果。
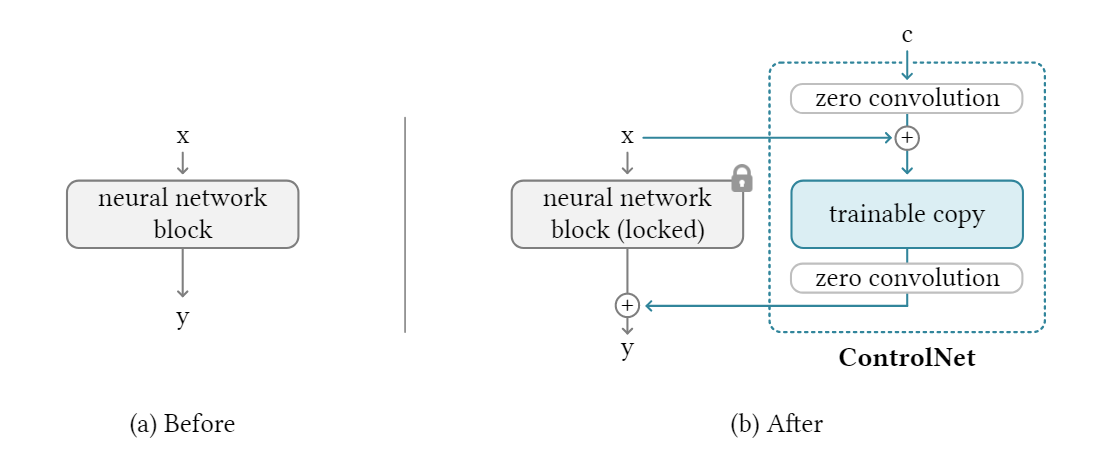 以 2D 图像为例,给定一张图像(特征图) , 分别代表高度,宽度,深度。一个将 x 转换为 y 的神经网络我们可以以将他记作
我们把 zero convolution(就是 1 1 卷积)记作 ,那么 ControlNet 就可以记作
由于 zero convolution 的权重初始为 0,那么就有
可以得出,即当 ControlNet 被应用到任何一个网络上时,不会对这个网络的效果产生任何影响。它完美保留了任何神经网络块的能力、功能和结果质量,任何进一步优化都将随着微调而变得很快。
以 2D 图像为例,给定一张图像(特征图) , 分别代表高度,宽度,深度。一个将 x 转换为 y 的神经网络我们可以以将他记作
我们把 zero convolution(就是 1 1 卷积)记作 ,那么 ControlNet 就可以记作
由于 zero convolution 的权重初始为 0,那么就有
可以得出,即当 ControlNet 被应用到任何一个网络上时,不会对这个网络的效果产生任何影响。它完美保留了任何神经网络块的能力、功能和结果质量,任何进一步优化都将随着微调而变得很快。
在训练过程中,作者随机的将 50%的 prompt 换成了空的 prompt,作者认为这可以增强模型从文本内容识别语义信息的能力。这主要是因为当 stable diffusion 模型看不到提示时,decoder 倾向于从输入控制图中学习更多的语义作为提示的替代品。
ControlNet 还给出了在个人电脑和大型计算集群上进行训练的方式。当计算设备有限时,作者发现部分打破 ControlNet 与 stable diffusion 之间的联系可以加速收敛。默认情况下是将 ControlNet 连接到“SD Middle Block”和“SD Decoder Block 1,2,3,4”(stable diffuion 的模块)。作者发现,只连接 Middle Block 而不连接 Decoder Block 1,2,3,4 可以将训练速度提高 1.6 倍(在 RTX 3070TI 笔记本电脑 GPU 上测试)。当模型在结果和条件之间表现出合理的关联时,这些断开连接的链接可以在持续训练中再次连接,以促进精确控制。
openai 在论文还比较了在不同的数据集上不同的编码器的效果

MutilDiffusion27 将图片分为几个部分分别进行 diffusion,然后将他们拼在一起通过一个全局去噪网络可以更好的控制生成图片中物体的位置。
DreamBooth
DreamBooth25 是 Google 提出的一个通过少量图片微调 diffusion model 的方法。
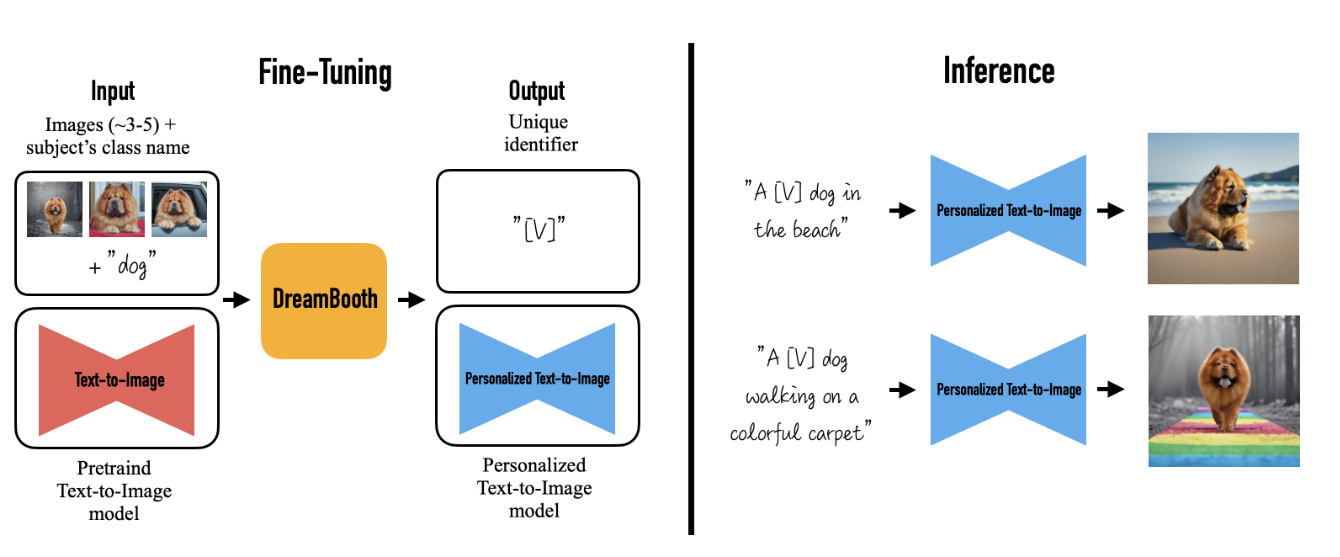 要训练自己数据最直观的方法,就是把自己的图片加入模型迭代时一起训练。但会带来两个问题,一个是过拟合,另一个是语义漂移(language drift)。总的来说 DreamBooth 的贡献在两方面,一方面是给定主题可以生成特定的主题的图片,一方面给定少数镜头微调 diffusion model 的方法同时保留输入图片的语义信息。 而 Dreambooth 的优势就在于能避免上述的两个问题。主要方法就是使用一个具有特殊含义而且比较少见的词,训练的图片最好有不同角度和光线下的图片。下图是 DreamBooth 论文给出的不同模型效果的对比图
要训练自己数据最直观的方法,就是把自己的图片加入模型迭代时一起训练。但会带来两个问题,一个是过拟合,另一个是语义漂移(language drift)。总的来说 DreamBooth 的贡献在两方面,一方面是给定主题可以生成特定的主题的图片,一方面给定少数镜头微调 diffusion model 的方法同时保留输入图片的语义信息。 而 Dreambooth 的优势就在于能避免上述的两个问题。主要方法就是使用一个具有特殊含义而且比较少见的词,训练的图片最好有不同角度和光线下的图片。下图是 DreamBooth 论文给出的不同模型效果的对比图

Cascade EF-GAN
Cascade EF-GAN28 是一种级联式的人脸编辑方式,可以更好地保留与身份相关的特征和细节,特别是在眼睛、鼻子和嘴巴周围,进一步帮助减少生成的面部图像中的伪影和模糊。
作者设计了一种级联式网络,同原本对一张人脸做更改变成了对一张人脸和脸上几个部分同时做更改。因为对一个人类来说分辨一个人的方式就是看人的眼睛,鼻子和嘴巴。Cascade EF-GAN 能够识别面部表情编辑中局部重点的重要性,并通过几个局部重点捕捉身份相关特征,有效地减轻编辑产生的伪影和模糊。
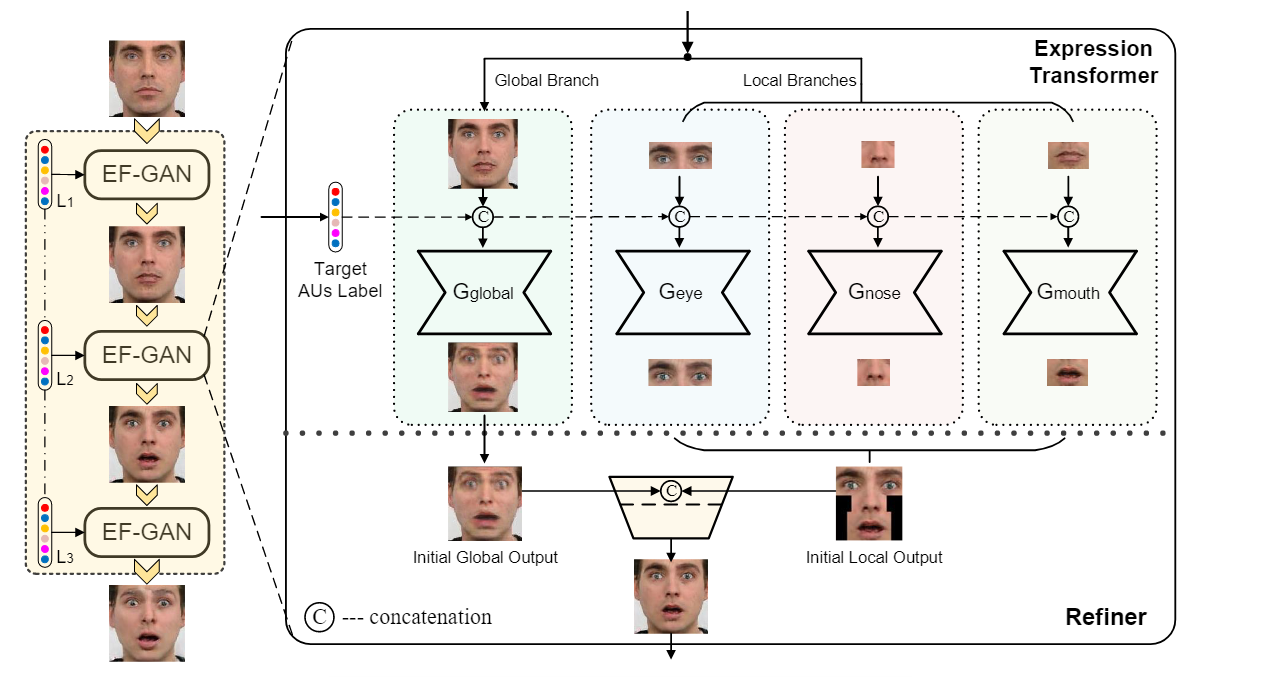
Cascade EF-GAN 中的生成模型由一个 Expression Transformer 和一个 Refiner 组成。Expression Transformer 执行带有局部焦点的表情编辑,Refiner 融合表情转换器的输出并细化最终编辑。
Expression Transformer 通过在全局和局部分支中处理面部图像来解决这个问题,其中全局分支捕获全局面部结构,局部分支专注于更详细的面部特征。Transformer 将面部图像和目标表情标签作为输入。所有分支共享相似的网络架构,但不共享权重
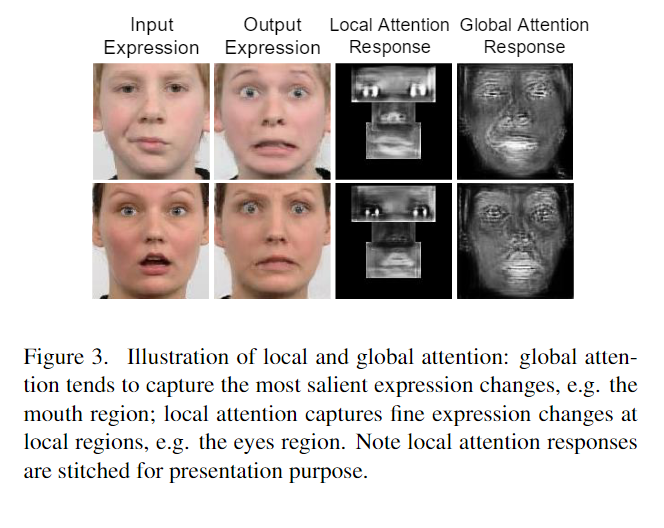
此外注意力被引入到全局和局部分支,以更好地捕捉细节和抑制伪影。在 GANimation [32]中,使用视觉注意力来引导网络集中于转换与表情相关的区域。然而,在单个全局图像中应用注意力往往会引入模糊的注意力响应,如图 3 的第 4 列所示。这是因为全局注意力倾向于关注最显著的变化,例如图 3 中的嘴部区域,而眼睛和鼻子周围的细微变化则没有受到足够的关注。前面提到的局部分支中的独占式注意力有助于在局部区域实现更锐利的响应,如图 3 的第 3 列所示。
每个分支输出颜色特征图 M*C 和注意图 M_A。对于原始输入图像 I_in,每个分支的初始输出通过以下方式生成
Refiner 负责融合表情转换器不同分支的输出,生成最终的表情编辑。如图 2 所示,三个局部分支的输出首先根据它们在面部图像中的各自位置缝合成单个图像。缝合的图像然后与全局分支的输出连接,并馈送到细化器以生成最终的表情编辑。
prompt2prompt
prompt2prompt5 是 Google 提出的一种基于 Imagen 的图像编辑方法,相比于直接 text2image 生成,文本引导图片生成要求原来图像绝大部分区变化不大,先前的方法需要用户指定 mask 来引导生成。prompt2prompt 的主要方法是将交叉注意力机制引入 diffusion 中,得到每个 token 对应的 attention map,一种有三种操作的方式
- token 换词,那么直接替换 attention map 即可。
- 加词,则是直接在对应位置加入新的 attention map。
- token 增强——直接提高对应的 map 的权重。
但这种方法也有一些局限,例如需要用户给一个合理的 prompt,细节的生成不太好,不能对图中的物体进行移位操作。
InstructPix2Pix
InstructPix2Pix29 是一种无需微调就可以快速编辑图像的方法,结合了两个大型预训练模型的知识——语言模型和文本到图像模型——生成了大量的图像编辑示例数据集。通过在这些数据上进行训练,并在推理时能够适用于真实图像和用户编写的指令。但也有一些局限例如数据带来的偏差,能会对图像进行不必要的过度更改。
多模态
多模态学习是指从多个模态表达或感知事物。 多模态可归类为同质性的模态,例如从两台相机中分别拍摄的图片,异质性的模态,例如图片与文本语言的关系。Jeff Dean 在 2019 年年底 NeurIPS 大会上的一个采访报道,讲到了 2020 年机器学习趋势:多任务和多模态学习将成为突破口。
CLIP
CLIP16 是 openai 关于文本和图像的一片工作,采用对比学习实现了图片的理解。
AudioCLIP 在原本的 CLIP 架构中加入了声音的模态。
I3D
I3D30 是一个视频理解模型,采用双流网络的架构,他的核心贡献是提出了如何对 2d 网络进行膨胀操作,同时提出了一个新的数据集 Kinetics
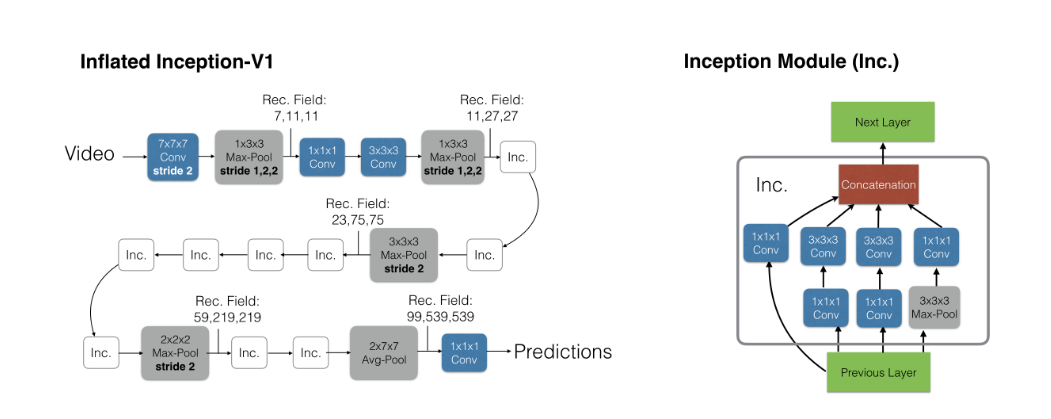
这篇文章提出的模型被称为 Two-Stream Inflated 3D ConvNets
Inflate 是模型的核心操作,含义是将一个 2d 模型”膨胀”成 3d 模型,做法很简单,就是把一个 的层变成 ,同时也将参数复制了 遍。
Segement anything
Segement anything31 是 meta 最近一篇图像分割的工作,使用一个 SOTA 的 zero-shot 目标检测器提取物体 box 和类别,然后输入给 SAM 模型出 mask,使得模型可以根据文本输入检测和分割任意物体。
在社区的努力下,实现了 Segement anything 和 stable diffusion 的协同32
ImageBind
ImageBind33 是 meta 的最新工作,是一个学习六种不同模态的方法-图像、文本、音频、深度、温度和 IMU 数据。此外在学习过程中不需要提供所有模态的信息,作者发现只要将每个模态的嵌入对齐到图像嵌入,就会导致所有模态的 emergent alignment(涌现现象)。
ImageBind 的目标是通过使用图像将所有模态绑定在一起,学习所有模态的单一联合嵌入空间。通过使用 Web 数据将每个模态的嵌入与图像嵌入对齐,例如使用带有 IMU 的自我中心相机捕获的视频数据将文本对齐到图像,将 IMU 对齐到视频,最后可以获得 zero-shot 的能力。然而,一个模态的不能直接应用于其他两个模态的组合,例如视频不能直接在图片-IMU 上使用。
IMAGEBIND 使用模态对 , 其中代表图像,是另一种模态,来学习单个联合嵌入.作者使用包含广泛语义概念的(图像,文本)配对的大规模网络数据集。也使用其他模态本身的自我监督配对,如音频、深度、热和惯性测量单元(IMU)与图像。使用 InfoNCE34损失优化嵌入和编码器。
尽管 ImageBind 只是用了六种模态进行训练,但是未来可以使用更多的数据和模态进行训练,将实现更丰富的以人为中心的 AI 模型。
prompt
prompt 提示可以给文字生成图片提供语义信息。
CLIP
CLIP16 使用了A photo of a {object}作为 prompt,object 是推理过程中的选择项,作者也讨论了大量的 prompt 相关的问题。一个常见的问题是一词多义。当一个类的名称是提供给 CLIP 文本编码器的唯一信息时,由于缺乏上下文,它无法区分哪个词的含义。在某些情况下,同一个单词的多个含义可能作为不同的类包含在同一个数据集中。另一个问题是,在我们的预训练数据集中,与图像配对的文本只是一个单词的情况相对较少。通常文本是一个完整的句子,以某种方式描述图像。通过使用A photo of a {object} 就可以使 ImageNet 的准确率提高 1.3%。作者还发现在不同的数据集上使用不同的 prompt 可以取得不同的结果。
ControlNet
在 ControlNet4 模型采取了三种 prompt
- No prompt:也就是""
- Default prompt:由于 stable diffusion 本质上是使用 prompt 进行训练的,因此空字符串可能是模型的意外输入,如果没有提供提示,SD 往往会生成随机纹理图。更好的设置是使用无意义的提示,“an image”, “a nice image”, “a professional image”,etc。在作者的设置中,使用”a professional, detailed, high-quality image”作为 default prompt。
- Automatic prompt:为了测试 fully automatic pipeline 的 SOTA,作者还尝试使用 fully automatic pipeline(例如,BLIP)使用“default prompt”模式获得的结果生成 prompts。作者会使用生成的提示再次扩散。
- User prompt:用户自定义的输入
prompt2prompt
prompt2prompt5的操作就是通过 prompt 进行的。
CLIP-interrogator
在背景图生成这个任务下有一个可能需要的步骤,从给出的人物图得到一些 prompt 生成图片,CLIP-interrogator 就是为了这样的任务而生的,开源的有 CLIP-Interrogator3536 和 CLIP-Interrogator237 .模型主要通过 CLIP 对以后数据集进行匹配获取 prompt、而通过 BLIP 获得图像最直观的理解。Code 底层也是需要 CLIP 和 BLIP 作为核心完成后面的工作。
数据集
WIT
openai 在 CLIP16 提到他们构建了一个新的数据集,从互联网上各种公开可用的资源中收集了 4 亿(图像,文本)对。为了尝试覆盖尽可能广泛的视觉内容,对每一类都有大概有 2000 对对整个数据集进行平衡。结果数据集的总字数与用于训练 GPT-2 的 WebText 数据集相似。这个数据集称为 WebImageText 的 WIT。
作者团队从直接与摄影师一起工作的提供商那里获得了一组新的高分辨率的 11M 图像。即使在下采样之后,这些图像的分辨率也明显高于许多现有的视觉数据集。
SA-1B
segment anything31 是 Meta 最新提出的一个用于目标分割的方法,他们为了更好的训练模型制作了一个迄今为止最大的分割数据集,1100 万张在 10 亿次授权且尊重隐私的图像上的数据集,同时开源了他们的数据集,此外还有一种 Data engine 的方法来快速生成数据集。
Data engine 分为三个阶段:(1)模型辅助手动注释阶段,(2)混合自动预测掩码和模型辅助注释的半自动阶段,以及(3)全自动阶段,
手动阶段
在第一阶段,类似于经典的交互式分割,一组专业注释者通过使用由 SAM 驱动的基于浏览器的交互分割工具点击前景/背景对象点来标记掩码。可以使用像素精确的“刷”和“擦除”工具来细化掩码。模型辅助注释直接在浏览器内实时运行(使用预先计算的图像嵌入),从而实现真正的交互体验。标注不受语义约束,可以自由地标注”stuff” and “things”
注释者被要求按突出顺序标记对象,一旦掩码需要超过 30 秒进行注释,便鼓励继续下一个图像。
在 SOTA 之后,SAM 就开始使用公共数据集进行训练,在经过了足够多的数据标注后,就用新标注的数据重新训练。随着收集更多的掩码,图像使用了 ViT-H 作为编码器。这样的模型训练一共进行了六次。随着模型的改进,每个掩码的平均注释时间从 34 秒减少到 14 秒。随着 SAM 的改进,每张图像的平均掩码数从 20 个掩码增加到 44 个掩码。总体而言,作者在这个阶段从 120k 张图像收集了 4.3M 掩码。
半自动化阶段
这个阶段的目标是增加 mask 的多样性。为了将标记集中在不太突出的对象上,首先自动检测 confident masks。然后向注释者展示了用这些掩码预先填充的图像,并要求他们注释任何额外的未注释对象。为了检测 confident masks,作者使用通用的“对象”类别在所有第一阶段掩码上训练了一个边界框检测器。在这个阶段,作者在 180k 图像中收集了一个额外的 5.9M 掩码(总共 10.2M 掩码)。在第一阶段,在新收集的数据(5 次)上定期重新训练模型。每个掩码的平均注释时间可以回到了到 34 秒(不包括自动掩码),因为这些对象对标签更具挑战性。每张图像的平均掩码数从 44 个掩码到 72 个掩码(包括自动掩码)。
全自动化阶段
这个阶段的主要目的是解决歧义
这个过程作者使用网格的点对图像进行预测,并为每个点预测一组可能对应于有效对象的掩码。如果说一个点位于一个部件或子部件上,我们的模型将返回子部分,部分和整个对象(subpart, part, and whole object)。利用模型中的 IoU 预测模块来选择 confident mask,IOU 阈值是 0.7,那么这个掩码就被认为是是稳定的。为了进一步提高小 mask 的质量,还处理了多个重叠的放大 mask。
Kinetics
Kinetics 是30 提出的一个视频理解数据集,Kinetics 有 400 个人体动作类,每个类有 400 多个例子,每个都来自一个独特的 YouTube 视频。
参考文献
Footnotes
-
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., & Ommer, B. (2022). High-Resolution Image Synthesis with Latent Diffusion Models. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Presented at the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA. https://doi.org/10.1109/cvpr52688.2022.01042 ↩ ↩2 ↩3 ↩4
-
Heathen. github.com/automatic1111/stable-diffusion-webui/discussions/2670, hypernetwork style training, a tiny guide, 2022. ↩ ↩2
-
Kawar, B., Zada, S., Lang, O., Tov, O., Chang, H., Dekel, T., … Irani, M. (2022). Imagic: Text-Based Real Image Editing with Diffusion Models. ↩ ↩2
-
Zhang, L., & Agrawala, M. (n.d.). Adding Conditional Control to Text-to-Image Diffusion Models. ↩ ↩2 ↩3
-
Mokady, R., Hertz, A., Aberman, K., Pritch, Y., & Cohen-Or, D. (2022). Null-text Inversion for Editing Real Images using Guided Diffusion Models. ↩ ↩2 ↩3
-
Song, Y., Dhariwal, P., Chen, M., & Sutskever, I. (n.d.). Consistency Models. ↩ ↩2
-
Poole, B., Jain, A., Barron, J., Mildenhall, B., Research, G., & Berkeley, U. (n.d.). DREAMFUSION: TEXT-TO-3D USING 2D DIFFUSION. ↩
-
Nichol, A., Jun, H., Dhariwal, P., Mishkin, P., & Chen, M. (2022). Point-E: A System for Generating 3D Point Clouds from Complex Prompts. ↩
-
Abbas, M., Kivinen, J., & Raiko, T. (2016). International Conference on Learning Representations (ICLR). ↩
-
Alaluf, Y., Tov, O., Mokady, R., Gal, R., & Bermano, A. (2021). HyperStyle: StyleGAN Inversion with HyperNetworks for Real Image Editing. ↩
-
Dinh, TanM., Tran, A., Nguyen, R., & Hua, B.-S. (n.d.). HyperInverter: Improving StyleGAN Inversion via Hypernetwork. ↩
-
Sohl-Dickstein, J., Weiss, EricL., Maheswaranathan, N., & Ganguli, S. (2015). Deep Unsupervised Learning using Nonequilibrium Thermodynamics. ↩
-
Ho, JonathanC., Jain, A., & Abbeel, P. (2020). Denoising Diffusion Probabilistic Models. ↩ ↩2
-
Ronneberger, O., Fischer, P., & Brox, T. (2015). U-Net: Convolutional Networks for Biomedical Image Segmentation. In Lecture Notes in Computer Science,Medical Image Computing and Computer-Assisted Intervention – MICCAI 2015 (pp. 234–241). https://doi.org/10.1007/978-3-319-24574-4_28 ↩
-
Song, J., Meng, C., & Ermon, S. (2020). Denoising Diffusion Implicit Models. ↩
-
Radford, A., Kim, J., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., … Sutskever, I. (2021). Learning Transferable Visual Models From Natural Language Supervision. ↩ ↩2 ↩3 ↩4 ↩5
-
Li, Y., Fan, H., Hu, R., Feichtenhofer, C., & He, K. (2022). Scaling Language-Image Pre-training via Masking. ↩
-
Yang, Y., Huang, W., Wei, Y., Peng, H., Jiang, X., Jiang, H., … Research, M. (n.d.). Attentive Mask CLIP. ↩
-
Nichol, A., Dhariwal, P., Ramesh, A., Shyam, P., Mishkin, P., McGrew, B., … Chen, M. (n.d.). GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models. ↩
-
Ramesh, A., Dhariwal, P., Nichol, A., Chu, C., & Chen, M. (n.d.). Hierarchical Text-Conditional Image Generation with CLIP Latents. ↩
-
Saharia, C., Chan, W., Saxena, S., Li, L., Whang, J., Denton, E., … Norouzi, M. (n.d.). Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding. ↩
-
Hu, EdwardJ., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., & Chen, W. (2021). LoRA: Low-Rank Adaptation of Large Language Models. ↩
-
cloneofsimo. (n.d.). GitHub - Cloneofsimo/lora: Using Low-rank adaptation to quickly fine-tune diffusion models. GitHub. Retrieved May 13, 2023, from https://github.com/cloneofsimo/lora ↩
-
LC1332. (n.d.). GitHub - LC1332/Chinese-alpaca-lora: 骆驼:A Chinese finetuned instruction LLaMA. Developed by 陈启源 @ 华中师范大学 & 李鲁鲁 @ 商汤科技 & 冷子昂 @ 商汤科技. GitHub. Retrieved May 13, 2023, from https://github.com/LC1332/的应用包括文字生成图片和图片生成图片,Chinese-alpaca-lora ↩
-
Ruiz, N., Li, Y., Jampani, V., Pritch, Y., Rubinstein, M., & Aberman, K. (2022). DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation. ↩ ↩2 ↩3
-
Low-Rank adaptation of large language models (lora). (n.d.). Retrieved May 13, 2023, from https://huggingface.co/docs/diffusers/training/lora#dreambooth ↩
-
Bar-Tal, O., Yariv, L., Lipman, Y., & Dekel, T. (2023). MultiDiffusion: Fusing Diffusion Paths for Controlled Image Generation. ↩
-
Wu, R., Zhang, G., Lu, S., & Chen, T. (2020, March 12). Cascade EF-GAN: Progressive facial expression editing with local focuses. arXiv.Org. https://arxiv.org/abs/2003.05905 ↩
-
Brooks, T., Holynski, A., & Efros, AlexeiA. (2022). InstructPix2Pix: Learning to Follow Image Editing Instructions. ↩
-
Carreira, J., & Zisserman, A. (2017). Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset. 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Presented at the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI. https://doi.org/10.1109/cvpr.2017.502 ↩ ↩2
-
Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., … Girshick, R. (n.d.). Segment Anything. ↩ ↩2
-
IDEA-Research. (n.d.). GitHub - IDEA-Research/Grounded-Segment-Anything: Marrying grounding DINO with segment anything & stable diffusion & tag2text & BLIP & whisper & chatbot - Automatically detect , segment and generate anything with image, text, and audio inputs. GitHub. Retrieved May 13, 2023, from https://github.com/IDEA-Research/Grounded-Segment-Anything ↩
-
Girdhar, R., El-Nouby, A., Liu, Z., Singh, M., Alwala, K., Joulin, A., & Misra, I. (2023). ImageBind: One Embedding Space To Bind Them All. ↩
-
Oord, A., Li, Y., & Vinyals, O. (2018). Representation Learning with Contrastive Predictive Coding. ↩
-
CLIP interrogator. (n.d.). A Hugging Face Space by Pharma. Retrieved April 19, 2023, from https://huggingface.co/spaces/pharma/CLIP-Interrogator ↩
-
pharmapsychotic. (n.d.). GitHub - Pharmapsychotic/clip-interrogator: Image to prompt with BLIP and CLIP. GitHub. Retrieved April 19, 2023, from https://github.com/pharmapsychotic/clip-interrogator ↩
-
CLIP interrogator 2. (n.d.). A Hugging Face Space by Fffiloni. Retrieved April 19, 2023, from https://huggingface.co/spaces/fffiloni/CLIP-Interrogator-2 ↩
