Imagic笔记
文字生成图片
Imagic笔记
先前的工作大多数方法目前仅限于以下一种:特定的编辑类型(例如,对象叠加,样式转换),合成生成的图像,或需要一个共同对象的多个输入图像。文章作者展示了将复杂的基于文本的语义编辑应用于单个真实图像的能力。与之前的工作相反,这篇文章提出的方法只需要一个输入图像和一个目标文本(所需的编辑)。它生成一个与输入图像和目标文本一致的文本嵌入,同时微调扩散模型以捕获特定于图像的外观。
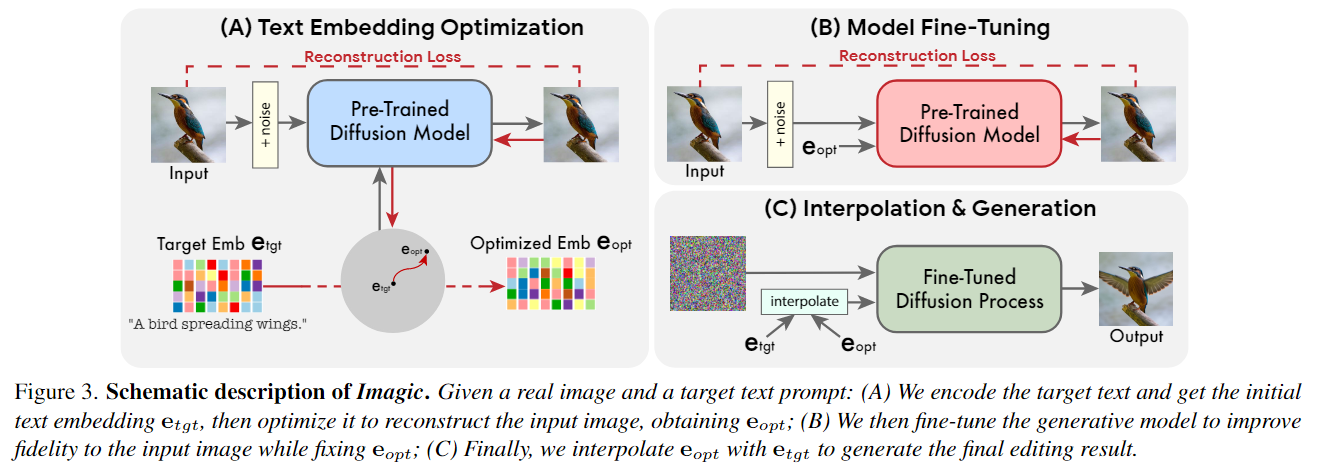
扩散模型是一种强大的最先进的生成模型,能够进行高质量的图像合成。在自然语言文本提示的条件下,它们能够生成与所请求的文本很好地对齐的图像。在工作中使用它们来编辑真实的图像,而不是合成新的图像。文章作者通过一个简单的3步过程来实现这一点,如图所示:首先优化文本嵌入,使其生成与输入图像相似的图像。然后,对预训练的生成扩散模型(以优化的嵌入为条件)进行微调,以更好地重建输入图像。最后,在目标文本嵌入和优化后的文本之间进行线性插值,得到一个结合了输入图像和目标文本的表示。然后将这种表示传递给带有微调模型的生成扩散过程,输出最终编辑的图像。
作者这进一步得到了一项人类感知评估研究的支持,在一项名为TEdBench -文本编辑基准的新基准测试中,评分者强烈倾向于图像而不是其他方法。
方法
作者将整个过程分成三个部分
- 优化文本嵌入,以在目标文本嵌入附近找到与给定图像最匹配的文本嵌入
- 微调扩散模型,以更好地匹配给定的图像
- 在优化的嵌入和目标文本嵌入之间进行线性插值,以找到一个既能达到输入图像的保真度又能达到目标文本对齐的点。
Text embedding optimization
目标文本首先通过文本编码器,它输出其对应的文本嵌入 ,其中是给定目标文本中的标记数,是标记嵌入维数。然后冻结生成扩散模型的 参数,并使用[[DDPM]]目标优化目标文本嵌入.其中 , 是使用和方程1获得的x(输入图像)的噪声版本,是预训练的扩散模型权重。这将产生与输入图像尽可能匹配的文本嵌入。作者运行这个过程的步骤相对较少,以保持接近最初的目标文本嵌入,获得。这种接近性在嵌入空间中实现了有意义的线性插值,而对于遥远的嵌入不表现出线性行为。
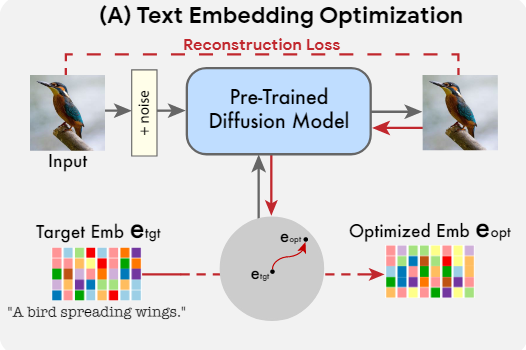
Model fine-tuning
请注意,当经过生成扩散过程时,得到的优化嵌入并不一定会导致输入图像,因为作者的方法优化运行了少量步骤(见图7中的左上角图像)。因此,在方法的第二阶段,通过使用公式2中所示的相同损失函数优化模型参数来缩小这一差距,同时冻结优化的嵌入。这个过程移动模型以适应输入图像在点处的位置。同时,微调底层生成方法中出现的任何辅助扩散模型,例如超分辨率模型。作者用相同的重构损失对它们进行微调,但以为条件,因为仅针对基本模型进行了优化。这些辅助模型的优化确保了保留基本分辨率中不存在的的高频细节
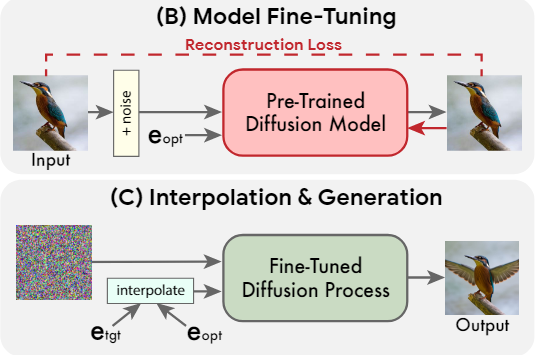
Text embedding interpolation
由于生成扩散模型被训练为在优化的嵌入处完全重建输入图像,作者使用它来应用所需的编辑,从而沿着目标文本嵌入的方向前进。更正式地说,第三阶段是和之间的简单线性插值。对于给定的超参数,就得到了 这是表示期望编辑图像的嵌入。然后,应用基础生成扩散过程使用微调模型,条件是。这将导致低分辨率的编辑图像,然后使用微调辅助模型,以目标文本为条件进行超分辨。这个生成过程输出最终的高分辨率编辑图像。
实验
消融实验
作者在消融研究中发现微调会强制引入来自输入图像的细节,超出了仅优化的嵌入,使他们的方案能够保留这些细节用于中间的η值,从而实现语义上有意义的线性插值。因此作者得出结论,模型微调对其方法的成功至关重要。
作者尝试了尝试了文本嵌入优化步骤的数量。作者通过实验表明通过较少的步骤优化文本嵌入将限制模型的编辑能力,而通过超过100步的优化几乎没有额外的价值。
局限性
作者在研究中发现了两种方法失败的情况:一种是所需编辑的效果非常微弱(如果有的话),因此与目标文本不太匹配;另一种是编辑效果很好,但会影响到外部图像细节,如缩放或摄像机角度。作者在第10张图中分别展示了这两种失败情况的示例。当编辑效果不够强烈时,增加η通常可以实现期望的结果,但在少数情况下会导致原始图像细节的显著丢失(对于所有测试的随机种子)。至于缩放和摄像机角度的变化,这通常发生在我们从低η值逐渐增加到较大值时,因此很难避免。作者在附录中展示了这一点,并在TEdBench中包含了额外的失败案例。这些局限性可能可以通过不同的方式优化文本嵌入或扩散模型来缓解,或者类似于Hertz etal.的交叉关注控制。作者将这些选项留给未来的工作。

此外,由于该方法依赖于预训练的文本到图像扩散模型,因此继承了模型的生成限制和偏见。因此,当所需编辑涉及生成底层模型的失败案例时,会产生不必要的伪像。例如,Imagen在人脸方面的生成性能不佳
结论和未来的工作
作者认为下一步的工作主要有两个方面
- 一是进一步提高算法对输入图像的准确性和对身份的保护,同时增强对随机种子和插值参数 η 的敏感性;
- 二是开发自动选择每个请求编辑的 η 值的方法
社会影响方面作者则认为模型容易受到基于文本的生成模型的社会偏见的影响,这些技术可能被恶意方用于合成虚假的图像以误导观众。为了缓解这种情况,需要进一步研究如何识别合成编辑或生成内容
