Cascade EF-GAN笔记
文字生成图片
Cascade EF-GAN
Cascade EF-GAN可以更好地保留与身份相关的特征和细节,特别是在眼睛、鼻子和嘴巴周围,进一步帮助减少生成的面部图像中的伪影和模糊。
模型架构
作者设计了一种级联式网络,同原本对一张人脸做更改变成了对一张人脸和脸上几个部分同时做更改。因为对一个人类来说分辨一个人的方式就是看人的眼睛,鼻子和嘴巴。Cascade EF-GAN能够识别面部表情编辑中局部重点的重要性,并通过几个局部重点捕捉身份相关特征,有效地减轻编辑产生的伪影和模糊。
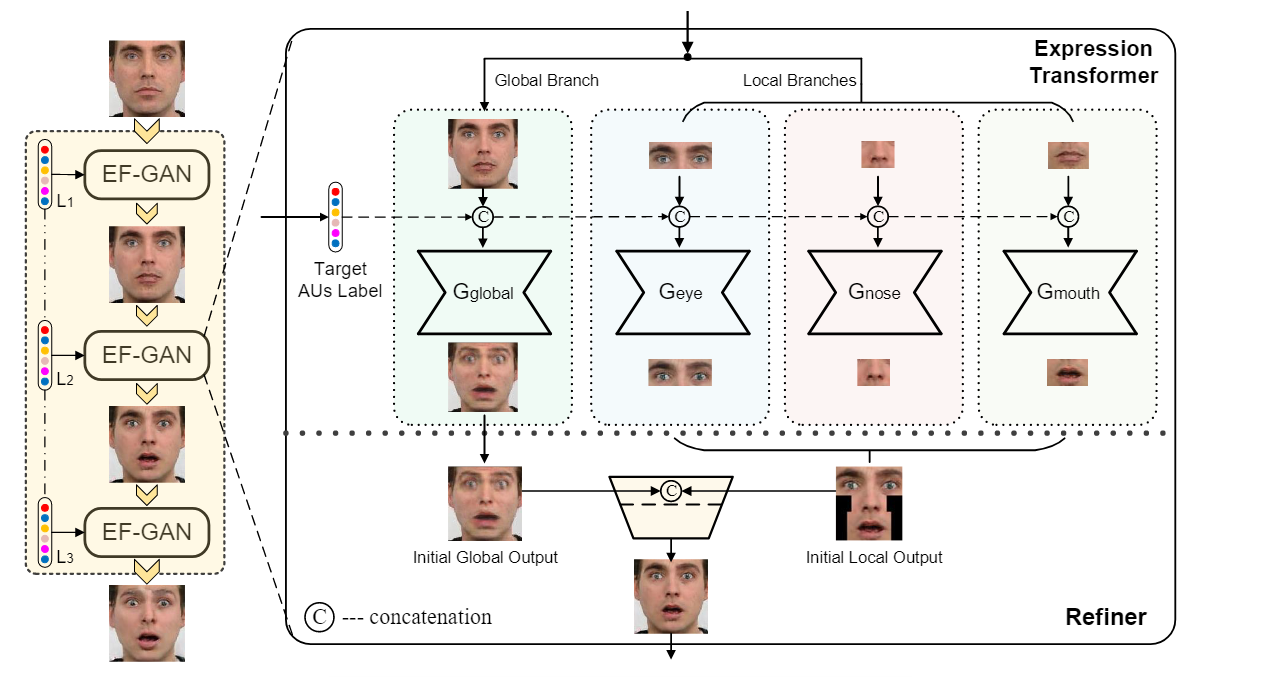
Cascade EF-GAN中的生成模型由一个Expression Transformer和一个Refiner组成。Expression Transformer执行带有局部焦点的表情编辑,Refiner融合表情转换器的输出并细化最终编辑。
Expression Transformer通过在全局和局部分支中处理面部图像来解决这个问题,其中全局分支捕获全局面部结构,局部分支专注于更详细的面部特征。Transformer将面部图像和目标表情标签作为输入。所有分支共享相似的网络架构,但不共享权重
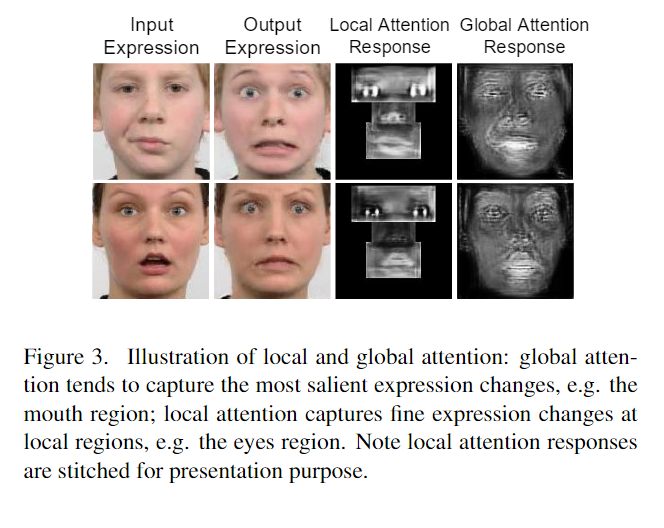
此外注意力被引入到全局和局部分支,以更好地捕捉细节和抑制伪影。在GANimation [32]中,使用视觉注意力来引导网络集中于转换与表情相关的区域。然而,在单个全局图像中应用注意力往往会引入模糊的注意力响应,如图3的第4列所示。这是因为全局注意力倾向于关注最显著的变化,例如图3中的嘴部区域,而眼睛和鼻子周围的细微变化则没有受到足够的关注。前面提到的局部分支中的独占式注意力有助于在局部区域实现更锐利的响应,如图3的第3列所示。
每个分支输出颜色特征图M_C和注意图M_A。对于原始输入图像I_in,每个分支的初始输出通过以下方式生成
Refiner负责融合表情转换器不同分支的输出,生成最终的表情编辑。如图2所示,三个局部分支的输出首先根据它们在面部图像中的各自位置缝合成单个图像。缝合的图像然后与全局分支的输出连接,并馈送到细化器以生成最终的表情编辑。
模型训练
如果直接级联多个EF-GAN模块并从零开始训练,很难获得良好的表达式编辑。作者推测,这在很大程度上是由于早期EF-GAN模块的噪声面部图像。将这些噪声较大的人脸图像作为输入,级联EF-GAN的后期很容易受到影响,产生较差的编辑效果。此外,还会积累不必要的编辑,使网络参数难以优化。
解决方式是先训练单个EF-GAN执行单步面部表情转换,接着使用训练良好的EF-GAN的权重来初始化级联中所有后续EF-GAN,并微调所有端到端的网络参数。通过这种训练方案,级联中的每个EF-GAN模块都有很好的初始化,从而使中间的面部表情图像对后期学习有意义的表情转换信息变得有用。
